Making a Panoply Connection
This article covers:
- How to set up a connection to Panoply
- How to add datasets
- How to do connection overrides on a Panoply connection
- The supported Panoply data types and the respective Luzmo data type they are mapped to
1. How to setup a Panoply connection
Depending on whether you data warehouse in Panoply is using BigQuery or Redshift, the connector to use differs. You can find out what technology your data warehouse uses by going to the BI Connections page in Panoply.
In case your data warehouse is :
- BigQuery, you will use our BigQuery connector.
- Redshift, you will use our Redshift connector or Panoply branded connector.
1.1 Connect to your BigQuery based Panoply data warehouse
To make a connection to your Panoply:
- In Panoply, click on BI Connection and download the service account JSON file.
- In Luzmo, navigate to the Connections page, select New Connection, then select BigQuery from the New Connection modal. You'll be asked to provide a key and token:
- Key: the client-email value from the service account JSON file from step 1
- Token: the private-key value from the service account JSON file from step 1
Please refer to the examples in our developer documentation to find out how to create a connection to BigQuery using our API.
1.1 Connect to your Redshift based Panoply data warehouse
To make a connection to your Panoply:
- In Panoply, click on BI Connection to see your data warehouses details.
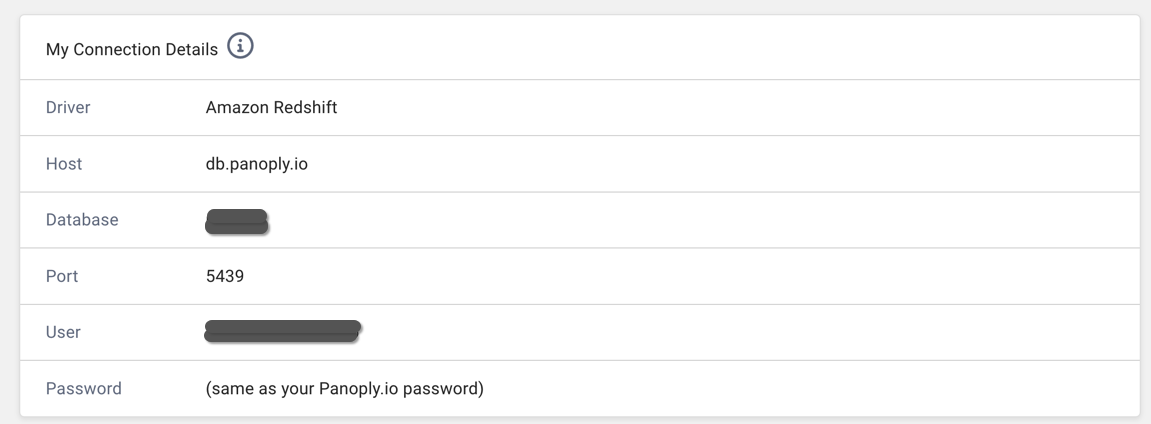
- In Luzmo, navigate to the Connections page, select New Connection, then select Redshift or Panoply from the New Connection modal. You'll be asked to provide a host, port, database, username and password
- host: the host to connect to, from the BI Connection page in Panoply
- port: the port to connect to, from the BI Connection page in Panoply
- database: the database to connect to, from the BI Connection page in Panoply
- username: the user to connect with, from the BI Connection page in Panoply
- password: the password to connect with, from the BI Connection page in Panoply
Please refer to the examples in our developer documentation to find out how to create a connection to Redshift using our API.
2. How to add datasets
2.1 How to add datasets for your BigQuery based Panoply
Once you have connected your Panoply you can add datasets as explained here.
- You can select one or multiple datasets as available in your Panoply and link them in Luzmo to ensure they can be used together in a dashboard.
- You can also add SQL datasets by switching to the SQL tab in the dataset creation modal. While creating or editing a SQL dataset, you can parameterize anything within the query by specifying
{{metadata.< parameter name >|< default value >}}. Find out more about parameterized SQL Datasets.
Also make sure to check out this article on Preparing your data for analytics.
To find out how to add datasets using our API, please refer to the examples in our developer documentation. For direct table import, specify a concatenation of the project, schema and table identifier, separated by a colon ':' and dot '.' (i.e. project:schema.table). You can find:
- the project ID on the BI Connection page in Panoply
- the schema and table on the Tables or Workbench page in Panoply.
2.2 How to add datasets for your Redshift based Panoply
Once you have connected your Panoply you can add datasets as explained here.
- You can select one or multiple datasets as available in your Panoply and link them in Luzmo to ensure they can be used together in a dashboard.
- You can also add SQL datasets by switching to the SQL tab in the dataset creation modal. While creating or editing a SQL dataset, you can parameterize anything within the query by specifying
{{metadata.< parameter name >|< default value >}}. Find out more about parameterized SQL Datasets.
Also make sure to check out this article on Preparing your data for analytics.
To find out how to add datasets using our API, please refer to the examples in our developer documentation.
3. Panoply Connection Overrides
When generating an Authorization token to grant a user acces to your embedded dashboards it is possible to override the data source properties in the authorization request to dynamically use different properties. Find out more about connection overrides.
3.1 Connection Overrides for a BigQuery based Panoply
The fields available for overriding a Bigquery based Panoply connection are as follows:
- Connection ID: The ID of the Connection to be overridden. Retrieve the ID to specify as detailed here.
- key: The the client-email value from the service account JSON file from step 1
- token: the private-key value from the service account JSON file from step 1
- datasets: List of dataset-level overrides. Useful if you want to override only a single dataset in your dashboard or if you have a separate table per client. The SQL query of the dataset can also be overridden if it's a SQL dataset within Luzmo.
- schema: A concatenation of a Bigquery project and schema, separated by a colon ':' (i.e.
project:schema). You can find:- the project ID on the BI Connection page in Panoply
- the schema on the Tables or Workbench page in Panoply.
- table: The new table to query. You can find the table the schema on the Tables or Workbench page in Panoply.
- sql: The new SQL query to run (only for SQL datasets). Alternatively, you could also use parameterized SQL Datasets.
- schema: A concatenation of a Bigquery project and schema, separated by a colon ':' (i.e.
Our developer documentation has more info about connection overrides and an examples of Bigquery connection overrides.
3.2 Connection Overrides for a Redshift based Panoply
Please refer to the Redshift connector article.
4. Supported Data Types
Please refer to the BigQuery connector or Redshift connector articles.